How are Duplicates and Supersedes handled in Enviro Data?
For quality assurance and quality control (QA/QC) purposes, environmental projects generate duplicated data in a variety of ways. Care needs to be taken with this duplicated data at both the samples and analyses levels. Enviro Data can handle duplicated data at both the samples and analyses levels. To import this duplicated data, the system uses two fields, DuplicateSample and Superseded, which are numeric fields in the Samples and Analyses tables respectively.
Duplicate Samples.
Duplicate sample are one or more additional samples taken from the same station at the same time to check the quality of the sampling, shipping, and analysis processes. This information is stored in the DuplicateSample field in the Samples table.
At the sample level, this data could be QA/QC data associated with an original sample such as a field duplicate. As an example, an original sample assigned a DuplicateSample number of zero might have a field duplicate taken on the same day, which would be assigned a DuplicateSample number of 1. The QCSampleCode in the Samples table is used to explain the meaning of the two samples, with perhaps a code of “Original” for the first sample, and a code of “Duplicate” for the second. Additional related samples are given higher DuplicateSample numbers. In some cases, the additional sample might be a second original sample instead of a QC sample. In this case, the QCSampleCode might be the same for both samples, however, in most cases the LabSampleID number would be different.
Enviro Data identifies unique samples based on the station, sample date, sample matrix, sample top, duplicate sample, sample bottom, filtered sample, field sample ID, QC sample code and alternate sample ID fields as seen in Figure 134 below. This allows the data administrator to import multiple samples related to one sampling event or make multiple imports of analyses from a given sampling event.
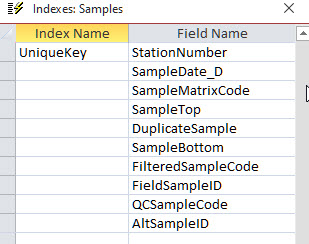
Figure 134 - Fields used to define the Unique Index in the Samples Table
Superseded Analyses
A superseded analysis is a duplicated result from one or more a re-analysis of the same sample for a single or group of parameters for QA/QC purposes. This results in duplicated or superseded results at the analyses level. In the industry these results can be represented in two ways, either as the original result plus the re-analysis, or as a superseded (replaced) original result plus the new unsuperseded result. This information is stored in the Superseded field in the Analyses table.
During import Enviro Data provides a way to supersede the original result value as this is more useful for selection purposes. You can choose tosupersded or replace (overwrite) a superseded result by checking or unchecking the Supersede Values If Present checkbox in the IMPORT WIZARD – OPTIONS AFTER CHECKING After Successful Check section. If this box is checked, a new analyses will supersed the old one. Otherwise, if it is unchecked, the new analyses will replace (overwriite) the old one. Either way, in the when selecting data you can easily choose to see just the most current (unsuperseded) data. Selecting the re-analyzed results is not as helpful because not all the parameters may have been re-analyzed.
Enviro Data identifies unique analyses based on sample number, parameter number, superseded, analytic method, leach method, report units, basis, filtered analyses code, QC analysis code and lab sample id fields as seen below in Figure 135 below. This allows the data administrator to import multiple analyses related to one sample or make multiple imports of analyses from a given sampling event. Re-analyses or analyses delivered at separate times are matched to the correct sample event by the import code using the unique fields listed above.

Figure 135 – Fields used to define the Unique Index in the Analyses table.
Discussion of Duplicates and Supersedes
Examples of data at these two levels, and the various fields that can be involved in the duplications at each level, are shown below.
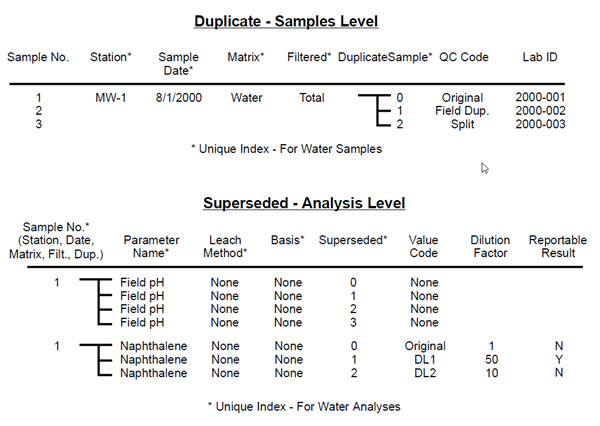
Figure 136 - Diagram of duplicates and supersedes
In the Sample Level example in Figure 136 above, there are three samples from the same well on the same date: an original sample, a field dup, and a split. These are represented with three different DuplicateSample numbers, and three different LabSampleID numbers.
In the Analysis Level there are superseded results for two different reasons.
In the field four different pH values were taken, most likely to confirm that the well chemistry had stabilized prior to taking a sample. The results have increasing superseded values from 0 to 3, with the 0 value being the most recent and presumably most representative value.
For naphthalene, multiple results were reported possibly due to matrix interference. The dilution factor for each result is shown. The original sample is reported with a superseded of zero, and the dilutions with higher superseded values. The ReportableResult field has been used to override which result will be reported. An alternative would have been for the data administrator to adjust the superseded values so the value for the result at a 50:1 dilution had a superseded value of 0 and it would be displayed by selecting a superseded value of 0 on the SELECT DATA form.
At the analyses level, the Superseded field is incremented when different analyses apply to the same sample and parameter. For example, multiple dilution analyses can be stored with incremented superseded values of 0, 1, 2, etc. Likewise, a re-analysis can be stored with a superseded value of zero (most recent data), while the original value remains in the database with a superseded value of 1. Note that this use of superseded values is the opposite of the more traditional view of new data for the same parameter as being a “re-analysis.” Experience has shown that while both the superseded and re-analysis view of the data validly describe what happened, the superseded approach is more useful for selecting data, since you can select the “unsuperseded” data (Superseded = 0) to suppress all but the most representative data. This is the default on the SELECT DATA form in the VIEWER program, so for the most part people get what they expect without much effort.
While you can manually change or delete the values in the Duplicate or Superseded Field Criteria boxes in the Select Data form, this form now had a dropdown control that will toggle them between a value of 0 (zero) and nothing (Null). This control can be found near the left side the Action Buttons Bar. “Display 0” is the default setting and how Enviro Data has historically opened the Select Data form. Caution: This should only be used to show the specific duplicated and/or superseded information when outputting data for calculations, exports, and reports.

The default is to leave this control set to “Display 0”. This means that both the Duplicated or Superseded Fields Criteria boxes will contain a 0 and duplicated or superseded data will NOT be provided in the dataset. If this control is changed to “Nothing”, the default of 0 is removed from both the Duplicate and the Superseded Fields Criteria boxes. The resulting dataset WILL contain every duplicated sample and every superseded result.
The ValueCode field provides a reason for the superseded value, such as re-analyzed, dilution, etc. however, the ValueCode field is not used to order the superseded sequence. The software sets Superseded values if one of the Duplicates and Supersededs options on the IMPORT WIZARD form, shown below, is selected as described in Duplicates and Supersededs on page 222.
![]()
Figure 137 - Duplicates & Supersededs settings in IMPORT WIZARD form
Correctly assigning QCSampleCode is crucial to identifying original vs. QC data as the QCSampleCode field is used to correctly identify original data vs. QC data for reporting. If you are importing data with QC sample information, you must populate the DuplicateOrder field in the QCCodes lookup table before importing as the Import Wizard uses this field to set your duplicate values based on the duplicate order.
Understanding duplicate and superseded values is very important for understanding QC and other data in Enviro Data. Selecting data based on duplicated and superseded values is discussed in Select Data section of the documentation.